 .
.
The Law of Effect: From Pigeons to Smartphones (and Unruly Children)
Marc Green
Overview: Edward Thorndike’s 1927 Law of Effect says that behavior followed by positive consequences is more likely to be repeated. It is seemingly obvious, yet the Law of Effect has often dismissed or ignored, although it is daily applied to us and by us, sometimes with dire consequences—any adaptive system that is beneficial can also be misled. This article takes a close look at the Law of Effect and the discipline of operant learning that it spawned. I briefly discuss the history and philosophy of Skinner’s operant behaviorism and explain basic concepts such as ”contingencies,“ which act like evolution to shape random variations into a final form. The discussion outlines the major types of “reinforcement” and punishment schedules, continuous (CRF), fixed and variable ratio (FR and VR), fixed and variable interval (FI and VI), and extinction (ext) and their differential effects on the strength, persistence, and pattern of behavior. The articles also explains how the contingencies shape the form of behavior and are a source of human adaptability through mechanisms such as “practical drift.” The discussion further covers the various types of reinforcers, contrasting primary (e.g, biological) vs. secondary (e.g., money) reinforcers and specific vs. generalized reinforcers. Although originally studied primarily in rats and pigeons, the same operant principles of “incentive structure” apply to many human behaviors such as gambling, smartphone addiction, and the rearing of unruly children. The article also briefly covers other learning mechanisms, respondent learning (Albert and the white rat) and implicit and statistical learning.
B. F. Skinner's most famous experiment was not an experiment but an observation. He placed eight hungry pigeons in their individual "Skinner boxes," cages with an automatic food dispenser. The dispensers were programmed to operate at random times, delivering food at unpredictable intervals regardless of what the pigeons were doing. When he later peered into the cages, he found that most (six) of the pigeons were performing a bizarre behavior; one kept spinning around in a circle, another stuck its head in the upper corner of the cage, while others bobbed their heads back and forth in a pendulum motion. The pigeons had exhibited none of these behaviors before the experiment. What had happened? The answer: the pigeons had adapted. But as Nassim Taleb would have said, they had been "fooled by randomness."
Incentives: The most powerful force in the world. When the incentives are crazy, the behavior is crazy. (Housel, 2023)
On several occasions such as the pages On Human Nature 1 and Understanding Human "Error," I have referred to Thorndike's Law of Effect1 and briefly defined it by saying that behavior followed by positive consequences is more likely to be repeated; behavior followed by negative consequences is less likely to be repeated. This may sound laughably obvious, but it is truly amazing how often this simple principle is overlooked. Repeatedly, society has suffered because those in power ignored the reality that incentive structure, the array of "contingencies" (see below), largely determines behavior. The law also explains why the "Fundamental Attribution Error" is an error—most people faced with the same incentives will be have in the same way. Moreover, the exact relationship between behavior and outcomes, the "contingencies," greatly affects the rate, persistence, and form of the resulting behavior. The contingencies explain behavioral phenomena ranging from the failure of many safety measures to the success of gambling casinos, the addictiveness of smartphones, and the creation of unruly children. As Housel says, crazy incentives create crazy behavior.
My purpose here is to explore the Law of Effect and to show how it promotes, discourages, and shapes behavior as the environment changes. I'll mostly be talking about "operant" (sometimes called "instrumental") learning, since it is the field of study that has primarily built on the original Law of Effect. The term "operant" refers to an organism's attempt to operate on the environment to produce a desired outcome.
Operant learning is most frequently associated with B. F. Skinner and the "behaviorist" school of psychology (Skinner, 1938) although he had many behaviorist predecessors, most prominently John Watson (see below). Much of operant research is performed with animals. When applied specifically to humans, the field is often called "applied behavior analysis" or "behavior modification" (although this term has frequently been corrupted). Operant learning underlies much of our adaptability, which is our great strength as a species. This is usually a good thing but when it comes to safety, the effects can be harmful. Safety always comes with a cost in terms of efficiency and/or money. Humans respond to the new situation by adapting their behavior, which may partially or completely null the safety intervention or even reverse it. As we saw with Skinner's pigeons, any adaptable system can sometimes be misled, but that is the cost of adaptability.
Humans have several types of learning mechanisms, but perhaps the two most basic are operant and respondent. Both are forms of associative learning whereby the actor connects two objects/events. Respondent learning is more popularly known as classical or Pavlovian conditioning. Here, the actor learns to associate a neutral "conditioned stimulus" (a CS like a bell) with a "unconditioned stimulus" (UCS, like food in the mouth). It has less applicability for present purposes, so I only discuss it briefly below. Other types of learning, such as implicit and statistical learning, differ from operant and respondent learning because they seemingly require no feedback. I'll briefly mention these as well.
Theoretical and Historical Background
For those unfamiliar with the history of experimental psychology, behaviorism was the dominant paradigm from about the 1930s until the 1960s, when the cognitive revolution took hold. B. F. Skinner believed that psychology needed an empirical foundation to be like the other sciences. Psychology had long used internal, invisible mental states as the causal agents of behavior. People acted because they were happy, sad, hungry, kind, friendly, etc. Since these inferred mental states are not overtly observable, Skinner and the other behaviorists concluded that they could not be scientifically studied by psychologists. Skinner did not simply dismiss the operations occurring in the brain but believed that what goes on between the ears is the domain of physiologists.
Moreover, inferred mental states lead to circular reasoning. Why did the person give you money? Because he is generous. How do you know that he is generous? Because he gave you money. Skinner and the other behaviorists recognized and attempted to avoid this circularity by focusing only on what is observable, environmental stimuli that can be defined physically and overtly and directly measurable behavior. In contrast, cognitive psychologists believe that the internal, inferred mental events are the central foci of psychology. They sneer(ed) at behaviorism as merely the study of meter readings, meaning overt behavior.
The idea of "behavior modification" a la the movie A Clockwork Orange also had an ideological aroma that academics did not like. The field is sometimes viewed as being one step this side of fascism because it could be used to control the behavior of other people or even whole populations. (This is ironic since Skinner was very much against the notion of authoritarian control by use of coercive measures.) Here's the reality: operant learning effects are a natural phenomenon. People already use reinforcement and punishment to alter each other's behavior, so the application of operant principles is a common, everyday occurrence. We use everything from flattery to financial incentives to modify other peoples' behavior to our liking and to discourage behavior that we don't like (timeouts sending children to their rooms). As far as controlling whole populations is concerned, one need only look at the IRS tax code and supermarket rewards programs to see operant techniques at work. Behaviorists are just scientists who examine this important, real-world phenomenon.
By the 1960s, however, the cognitivists had overwhelmingly won the battle, and operant psychology was sent packing to the academic hinterland, where it continues on without much fanfare as a science even though its practical applications are widespead. This is why most who study safety have never heard the term or understand its philosophy or basic concepts. To those people, I recommend Geller's excellent The Psychology of Safety Handbook.
The complete dismissal of operant learning is unfortunate. Behavior reflects adaptations to the environment and operant learning explains how many of those adaptations originate. Certainly, it does not explain all behavior, but much of behavior is readily explicable when looking at the operant contingencies and their schedules. Attempts to change behavior depend greatly on creating the right contingencies. Safety improvements that run contrary to the contingencies are futile. Lastly, operant learning never attempts to look into the person's mind. This can be an advantageous viewpoint when attempting to modify behavior. Humans are the least malleable part of any system. Operant learning focuses on changing behavior more effectively by using the contingencies (the environment) rather than directly changing the actor.
One other important aspect of the behavioristic program is often misunderstood. Skinner believed that positive reinforcement was a far superior method of behavior change compared to punishment. In his eyes, punishment only teaches people to change their behavior to circumvent the negative consequences. Moreover, punishment often produces highly undesirable emotional behaviors such as aggression. Behaviorists coined the term "behavior modification" to mean changing behavior through positive reinforcement. Like many scientific terms, it has unfortunately been misused by uninformed people who don't understand the field's basic precepts.
Last, Skinner saw behaviorism as the most optimistic possible view of human behavior. If all behavior is learned, then it can be changed for the better by rearranging the contingencies. To do this, it is necessary to understand how the arrangement of reinforcers affects behavior.
Perhaps the best way of thinking about operant behavior is as an analog to evolution. Presumably, natural selection causes those individuals with the most advantageous genes to survive while those without them eventually die out. Just as evolution selects genes, operant learning selects behavior by strengthening the good one and weakening the bad. It is faster than evolution because it operates on a much shorter time span, the life of the individual rather than the succession of generations. If our species could only adapt over generations, then human progress would have been much slower.
Basic Operant Learning Concepts
Contingencies
In operant learning, the key concept is the already-mentioned contingency. Other central concepts include "discriminative stimulus," "reinforcement,"2 and "punishment," reinforcement "schedules," and "shaping." To start, imagine than person perceives a discriminative stimulus (a particular sight, sound, person, situation, etc.) and then makes a response. There are the four possible consequences shown in the Figure 13.
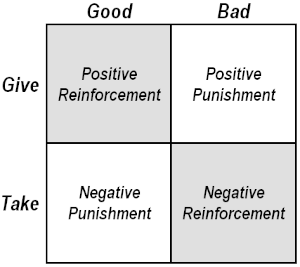 Figure 1 The Law of Effect contingency table of reinforcements and punishments.
Figure 1 The Law of Effect contingency table of reinforcements and punishments.
The gray squares show cases where behavior is made more probable and white squares where it becomes less likely. If the response delivers something good, it positively "reinforces" the behavior and makes it more probable, at least in the presence of the discriminative stimulus which "sets the occasion" for the response. Without the discriminative stimulus present, the behavior will not produce the reinforcement. If the outcome is bad, then the consequence is a positive punishment that weakens behavior. Again, this presumes the presence of a discriminative stimulus.
It is also possible to reinforce behavior negatively. Many people confuse negative reinforcement with punishment. The term "reinforcement" always means that the behavior is strengthened, as the word implies in normal English. Negative reinforcement is only negative in the sense that it operates by taking away something bad. For example, if a person with a headache takes a particular medicine and experiences headache relief, then the behavior of using that medicine is negatively reinforced and more likely to occur again. Lastly, negative punishment weakens behavior by taking away something good, i.e., refusing to let a child watch television in order to have him clean his room. In sum, behavior probability depends on the "contingencies," the relationship between behavior and outcome.
However, people often accidentally learn illusory contingencies. If a reinforcer follows a behavior, it strengthens the behavior whether or not a cause and effect relationship exists. It is merely necessary for the effect to follow the response in time. When there is no causal relationship, then the behavior is "superstitious." It is very easy to learn pointless or even harmful behavior through chance connections between behavior and outcome, like Skinner's pigeons. (It is also easy to draw wrong conclusions about the past and to ascribe causation where none existed. This is what Taleb meant by "fooled by randomness.")
It's worth stopping and saying a few words about pigeons4. While pigeons can adapt somewhat, their behavior is still tightly bound by genetic predisposition. They are so constrained that they easily fall into destructive behavior, as the "negative autoshaping"5 phenomenon demonstrates. Skinner has been rightly criticized for ignoring the reality that humans come pre-programmed with many limitations and predispositions which are not arbitrary behaviors that can be easily modified. I've already discussed a few in relationship to threat defensive reactions. In contrast to pigeons, however, human behavior is much less determined by genetics. However, humans are variable, so that reinforcers and their magnitudes vary from person to person. Humans with an "addictive personality,6" for example, may experience greater reinforcement magnitude for gambling or smoking than other people. Their behavior resembles that of pigeons, at least in some cases, because they may be constrained by innate physiology than other people.
It is very easy to learn pointless or even harmful behavior through chance connections between behavior and outcome. Skinner's pigeon study makes the point. The behavior was strengthened by the behavior-reinforcement temporal association even though there was no causal connection. The strengthened behavior was more likely to be repeated, so it was more likely to be accidentally occurring just prior to the next reinforcement. This made it even more probable, so it was even more likely to occur just before the next food delivery. The cycle of increased behavior probability followed by increased probability of reinforcement continued to build. Lest anyone think that this is a pigeon phenomenon, it is only necessary to consider rain dances, baseball players who don't shave while on a hitting streak, and the many other forms of human superstitious behavior7.
The pigeon study exemplifies a "wicked" environment. The benefits of operant (and other types of associative) learning depend on whether the environment is "kind" or "wicked." A kind environment reinforces the "good" behaviors that help achieve the goal, and never reinforces behavior that may be destructive or pointless. Conversely, "wicked" environments reinforce behavior that is immediately or ultimately destructive. One need only look at the 2008 financial meltdown to see how Wall Street bonus structures reinforced reckless, behavior. A principle job of anyone creating a new system or changing an old one is to ensure that the environment is kind. Of course, what is kind to the person creating the system is not necessarily kind to the people using it. That's all the more reason that everyone should understand how operant "conditioning" works.
Strength of reinforcement
Not all reinforcers are created equal. The first step is to appreciate the relative strength of different reinforcers (and punishments). Reinforcers vary in their power to affect behavior. The prime reinforcer variables are magnitude and delay. Greater magnitude reinforcers produce bigger behavioral change. However, reinforcer magnitude is sometimes difficult to estimate because it is situational and highly subjective. Moreover, the magnitude scaling problem exists. Is twice the amount of food twice as reinforcing? Lastly, many real-world reinforcers such as feeling a sense of control, receiving attention, and confirming a group/tribal identity are in the person's head and cannot be objectively quantified. The subjectivity of reinforcers is a limitation in applying operant principles.
While magnitude might seem an obvious factor in modifying behavior, it can play a surprisingly small role. Delay is often more important than magnitude. Reinforcers and punishments not received immediately after response quickly lose their potency. As the delay becomes longer, the effects of reinforcers and punishers weaken dramatically. A small gain now is often preferred to a large gain later. (Everyone knows that a bird in the hand is worth two in the bush.) In many cases, the delay pits a reinforcer against a punisher. Much "unsafe" behavior occurs because a small short-term gain dominates a very large long-term pain. A smoker receives the short-term reinforcement of smoking and the large long-term punishment of lung cancer. In many cases, the delay is accompanied by uncertainty in the outcome. The smoker may or may not develop cancer, further reducing the contingency's strength compared to the certain, and immediate reinforcement. This weakening of consequences due to delay is one of main reasons that safety is so hard.
Sometimes, people can cognitively bridge the temporal gap. A person may read newspaper articles saying that eating palm oil will contribute to clogged arteries and produce a heart attack sometime in the distant future, so he stops consuming palm oil right now. Such behavior generally occurs when there is a ready, "safer" alternative to receiving the short term gain, e.g., olive oil. Otherwise, cognitively bridging the gap is much more difficult.
In operant learning, there are two non-cognitive approaches for overcoming temporal delay. One is the creation of secondary reinforcers and the other is the use of schedules. Reinforcers fall into several categories. The most important distinction is between primary and secondary reinforcers. Primary roughly equates to innate and biological. Common examples include food (when hungry), water (when thirsty) and warmth (when cold). Some would further argue that emotions and feelings such as the need for attention, love, control, and self-esteem are less tangible but still primary reinforcers. Primary reinforcers can have great magnitude, but they may be limited in scope and ease of use. They may not be available at the appropriate time or place or easily manipulated to shape behavior. (Imagine trying to train employees by placing food in their mouths after every desired response.)
More often, stimuli that have no innate reinforcing properties, "secondary reinforcers," shape and maintain behavior. They are secondary because they only derive their power from association with a primary reinforcer. They can also bridge the delay from response to the eventual primary reinforcer. A standard type of operant study demonstrates a simple relationship between a primary and a secondary reinforcer. A pigeon that has had no food for twelve hours is placed in a box that contains a "key," a circular disk with a pressure switch mounted on a wall above a feeder. If the pigeon pecks the key when it is illuminated, then food falls into the feeder. When the key is dark, then pecks have no effect. The illuminated key is the discriminative stimulus for responding. The pigeon soon learns ("autoshapes") to peck the illuminated key in order to receive the food, the primary reinforcer. However, the pigeon has learned even more. It has learned that the key illumination precedes and predicts the food. The illuminated key and food are associated. The pigeon will then work (e.g., press a treadle) merely to illuminate the key. It has become a secondary reinforcer derived from the primary reinforcer. Further, secondary reinforcers can form chains. If a red light turned on above the box just before the key illuminated, the pigeon would learn to work in order to produce the red light because it predicted the illuminated key, which predicted the food.
Pigeons are not the only organisms that work for secondary reinforcers. Some have even suggested that secondary reinforcers form the basis of human society and the family. For example, Dollard & Miller (1950) proposed that the parent-child bond partly results from secondary reinforcement. The parent appears just before a baby receives the primary reinforcement of food. Since the parent becomes associated with food, the parent takes on a high value as a secondary reinforcer.
More generally, society largely shapes individual behavior using a type of secondary reinforcer called "money," which bridges the spatiotemporal gap between behavior and primary or even other secondary reinforcers. People work for money that they can later trade for objects with more directly reinforcing properties. For example, a worker earns money (first secondary reinforcer) so that he can pay his heating bill (secondary reinforcer) so he can be warm (primary reinforcer). Alternatively, he may work to buy candy. This could be a primary reinforcer if he eats it or a secondary reinforcer if he gives it to his girlfriend in hopes of obtaining affection. At the time the money is obtained, it is not even necessary to know the identity of the ultimate reinforcer. The secondary reinforcer, money, has a value of its own.
Reinforcers can also be "specific" or "generalized." The illuminated pigeon key is specific because it is associated with only one primary reinforcer, food. Money is a generalized secondary reinforcer because it can be later converted to a wide range of secondary and primary reinforcers. This wide applicability gives money an especially great reinforcing power.
Primary and secondary punishers also operate analogously to reinforcers. When punishers evoke strong negative emotions of fear of pain and suffering, they can produce powerful and fast behavior change through the mechanism of respondent learning, which is better known as classical or Pavlovian conditioning. One well-known example of respondent learning is "Albert and the white rat." Watson & Rayner (1920) placed an eleven-month old child with the pseudonym "Albert" next to a white rat. At first, Albert played happily with the rat8. When Albert next touched the rat, the researchers banged an iron bar behind his head to make a very loud noise. Albert quickly became distressed, cried, and stopped touching the rat. Afterward, Albert became afraid and cried even at the sight of the rat. The loud bang was an "unconditioned stimulus" (US) that produced the "unconditioned response" (UR) of fear. The US-UR connection was innate and needed no learning.
The connection between the rat and the fear was learned. The white rat was initially neutral and invoked no fear response. After it had been paired with the US, it became a "condition stimulus" (CS). The mere sight of the rat produced fear and crying, the "conditioned response" (CR) that was similar to the UR. The US-CS pairing is another form of associative learning.
This process resembles the operant development of secondary reinforcers. In both cases, the individual learns an association between an initially arbitrary stimulus and a non-arbitrary one. It is sometimes difficult to distinguish operant from respondent learning.
The Albert experiment highlights three other points. First, Albert also became upset by seeing objects such as a rabbit, a fur coat, and a Santa Claus mask as well as the rat. He exhibited "generalization," responding to stimuli similar but not identical to the original. Generalization also occurs in operant learning with positive reinforcement. Second, Albert's learning required only one trial. This is common when the UR/punisher is strong. A human analog occurs in some people who have had a major mishap. They avoid driving after a road collision or avoid flying after a near-crash. Cars and airplanes have become conditioned stimuli that evoke a fear CR. This is doubtless a reflection of innate human responses to threat. Third, Albert was repeatedly exposed to the rat without the bang ensuing, and the fear response faded over time. (It was not stated whether Albert's CR ever completely extinguished.) Similarly, a person who has a near miss initially drives more conservatively but usually gradually reverts back to his old behaviors over time (e.g., Yue, Yang, Pei, Chen, Song, & Yao, 2020) through "practical drift" (see below). In extreme cases, however, a person may develop a "phobia" that does not extinguish because the phobic avoids the CS, and even the proximity of the CS, so extinction never occurs.9
Perhaps the most important point about all reinforcers and punishers is that they control behavior. Organisms do not act randomly but rather they attempt to obtain reinforcement and to avoid punishment. As a result, understanding human behavior often begins by identifying the reinforcers and punishers that are operating on a particular person in a particular situation. Attempts to promote safety by changing behavior will be inefficient or even ineffective if they fail to consider the controlling reinforcers and punishers.
Schedules of reinforcement
Real-life is not as simple as Figure 1 suggests. The relationship between response and outcome is seldom perfect. There may not be a reinforcement (or punishment) following every response, even in the presence of a discriminative stimulus. Instead, reinforcements are often intermittent, occurring on different "schedules." The schedules are important because they produce behavior of different strengths, persistences, and patterns.
Table 1 lists the six basic schedule types. The simplest are continuous reinforcement (CRF), the reinforcement of every response, and extinction (EXT), the reinforcement of no responses10. The other four schedules are intermittent. In fixed ratio (FR X), reinforcement is delivered after every X responses. Fixed interval schedules (FI Y) reinforce after a period of Y has timed out. In contrast to fixed schedules, variable ratio (VR X) and variable interval (VI Y) reinforce irregularly. For example, a VR 10 would reinforce (or punish) on average every 10 responses. However, it might be after the third response in one case and after the fifteenth response the next time. Similarly, a VI 30 seconds would reinforce the first response on average every thirty seconds, but it might be after 60 seconds the first time and after 10 seconds then next. All the responder learns in a variable schedule is the "density" of the reinforcements. He can never know exactly when the next one will occur. He only knows that the probability is greater on a "fatter" schedule with a smaller VR or VI requirement or lower on a "leaner" schedule with a higher VR or VI requirement.
Table 1. The basic operant reinforcement schedules.
| Reinforcement Schedule | Explanation |
|---|---|
| Continuous (CRF) | Reinforce every response |
| Fixed Interval (FI) | Reinforce first response after time period X |
| Fixed Ratio (FR) | Reinforce first response after Y responses |
| Variable Interval (VI) | Reinforce first response after an average time period X |
| Variable Ratio (VR) | Reinforce response after an average of Y responses |
| Extinction (Ext) | Reinforce no response |
Responders learn faster and respond more often in fatter schedules. People respond at a higher rate on an FI 10 than on an FI 20, on a VR 10 than a VR 20, etc. CRF is the most potent because every response is reinforced. However, CRF has a major downside. It is the least persistent, meaning that if placed on extinction, the behavior soon ceases. The responder quickly notices the change from being reinforced every time to never being reinforced when switched to extinction. He will usually make a few more responses to confirm that the well has run dry, but he soon stops responding.
Fixed schedules also produce specific patterns of behavior. Responders learn the ratios and intervals and become good at predicting when reinforcement will become available. They respond in proportion to those probabilities. The classic example is the FI "scallop" on a graph of response probability versus time to reinforcement availability. The responder can't be exactly sure when the interval will time out, but he wants to obtain the reinforcement as soon as possible with as little effort as possible. At the beginning of the time interval, there is little response. As time passes, responding begins to increase slightly. As the time interval is about to expire, responding becomes very rapid. The pattern reflects the probability of reinforcement. The interval is unlikely to have timed out immediately after the last reinforcement, so responses are unlikely to be reinforced. As time passes, the probability that the interval is about to expire increases, so the responder tests the situation with more responses. Toward the interval end, responses have a high probability of being reinforced. By analogy look at the number of people at a bus stop ten, five, and one minutes before a bus is due. The same scallop occurs in the number of people waiting.
In FR, responders tend to run off the responses in a chain, as if they were a single response. The responder exhibits a "post-reinforcement pause" (PRP) after the reinforcement and does not respond again for an interval. The ratio must start again, so the next responses have no chance of being reinforced.
Variable schedules create lower but more persistent response rates. They are best for producing persistent behavior because they create the greatest uncertainty. The responder "believes" that he will receive reinforcement, but he doesn't know exactly which response will be reinforced. It could be the next one, or it could be after he expends much time and effort. Moreover, the uncertainty is high, so he will have great difficulty in discerning the reduction of reinforcement should the schedule be switched to lower density, e.g., from VI 25 to VI 50 or even to extinction.
This begs the question of how someone would get on a schedule such as FI 25 or VR 25 in the first place. It seems unlikely that anyone would learn a behavior that was reinforced only every 25th response. The answer is "shaping," the altering of behavior by gradually changing the reinforcement schedule. Shaping can be used to change rate and persistence. As described below, it can also change the form of behavior.
To get someone on a VR 25, for example, the standard technique would be to start on CRF (which is the same as VR 1) and then to gradually reduce reinforcement density. Once he is responding as desired on CRF, the density is lowered, say to VR 2. The responder will notice the change but will continue to make a few responses. On a fat schedule such as VR 2, chances are good that one of these extra responses will be reinforced. The responder learns that while not every response may be reinforced, many will. He keeps on responding, perhaps at a lower rate. When response rate stabilizes, then the VR schedule is increased to VR 4. Again, the responder may notice the fewer reinforcements, but he still never knows whether the next response is the one that will be reinforced. He then continues to respond for the eventual reinforcer. The game continues with the VR ratio increased gradually until reaching VR 25. The falling reinforcement probability, however, lowers response rate.
Creating "Addictions" and Unruly Children
Partial reinforcement schedules can produce very stable and persistent behavior even with very lean schedules. Gambling casinos exist because of it. Let the "sucker" win the first few (put him on a CRF or a low VR) and then gradually start increasing the ratio11. After a while, the gambler can lose almost every time but continues to play. It only requires a very infrequent win (reinforcement) to support the behavior and to keep it going. In pure games of chance like roulette, the behavior is as superstitious as the key-pecking of Skinner's pigeons.
If placed on extinction, it will take a long time for VR and VI responders to stop. The fatter the schedule, the sooner the responder realizes that the game is up and stops responding. However, it takes very few reinforcements to reinstate the behavior even after long periods of extinction. Moreover, no learned behavior ever truly disappears entirely. To use an old analogy, learning is like taking a new piece of paper and crumpling it up into a ball. You can lay it on a desk and try to smooth it out again, but the creases never go away completely. Placed under stress, the paper tends to revert to the crumpled form. Learned behavior is much the same. It can go extinguished for a long time, but people under stress tend to revert to old behaviors that have worked at some time in the past. This can lead to people acting in ways that seem thoroughly puzzling.
Smartphone email and social media addiction work the same way as gambling casinos. Users check their phones for email. If one has arrived, it reinforces the user, probably because it is a sign that someone is giving the user attention. However, there will not be an email message on every check. The user knows that there will be one eventually but cannot be sure exactly when. It is perfectly analogous to the gambler in the casino except that it is VI schedule—the probability of the reinforcer's appearance is based on time, not the number of responses made.
Social media apps are even more insidious. While email checking is a natural consequence of communication and is similar to autoshaping (self-shaping), the apps purposefully manipulate the user on to an VR schedule. The users look at their phones to see if the first video provides reinforcement. If not, then they just keep scrolling (making responses) because they know that one will appear if they just keep responding. Like the gambler, they are hooked on a VR schedule. The company behind the app strengthens response by keeping a low VR requirement, i.e., a fatter schedule, using an algorithm based on individual's likes and dislikes. The fatter schedules are also more likely to hook beginners because their VR requirement will be very low.
While gambling casinos and social media apps intentionally use produce persistent to produce desired behavior, it is very easy to train strong and persistent undesirable behavior by unintentional shaping. One common example occurs when parents attempt to deal with a whining, demanding child. The parent gives the child what he wants to have some peace and quiet. The child has just learned that whining is reinforced and soon does it again. The whining increases in frequency following reinforcement. Eventually, the parent decides that enough is enough and tries to stand firm. The next time the child whines, the parent does not give in immediately but only after the child persists. The parent capitulates and reinforces the child, who has now learned that he is no longer on CRF but rather on an intermittent schedule. Not every response will be reinforced, but eventually there will be a reinforcer.
The parent again decides that the whining has to stop so next time he holds out longer but eventually caves. The child is placed on an increasing VR schedule, never knowing when the reinforcement will occur, but he is confident that it will occur at some point if he persists. Eventually, the parent musters the strength to place the child on extinction, but by then the behavior is very persistent because it will take many, many, responses before the child learns that the behavior is pointless. Worse, even a single moment of weakness and instance of capitulation to whining makes the behavior extremely persistent by showing the child that if he keeps it up, he will be reinforced. He is just on a leaner schedule. The other problem is that the cessation of reinforcement will be a punishment that elicits emotional behavior.
Last, Table 1 does not exhaust the list of possible reinforcement schedules. For example, the "limited hold" is an alternative method to punishment for decreasing response frequency. The actor makes his first response, which sets a timer going. If he makes another response before the interval times out, the then timer resets to start the interval all over again. By lengthening the interval, shaping gradually forces a decrease in the frequency of response. This method has been used to get people off bad habits such as smoking12.
Shaping Behavior
So far, I've discussed factors that affect the strength and persistence of behavior. The contingencies can also shape behavior, transforming one response into another. Here's an example that I am highly familiar with. I once had to shape a rat in a "Skinner box" to press a "setup" key at one end of the box with its nose and then run to the other end and push a "response" key. For primary reinforcement, an electrode had been implanted in the "pleasure center" of the rat's brain. A wire to the electrode could deliver a jolt of current, which the rats apparently loved and served as a powerful and immediate reinforcer.
I first trained the rat to press the "response" key. I waited until the rat by chance wandered over to the half of the box where the setup key was located. I then delivered the reinforcement. After a few such jolts, he began spending most of his time on the correct side. I then changed the requirement so that he had to be within the third of the box nearest the setup key before receiving a reinforcement. If he moved away, there was no reinforcement. When he moved toward the desired direction, he was reinforced. Behavior always has some variability. In shaping, you wait for variation in the desired direction and strengthen it by reinforcement. Again, operant learning is analogous to evolution. Both posit a selection based on a random variation.
The procedure continued by changing to successive requirements that he was within a few inches of the key, then that his nose moved toward the key, then that his nose touched the key, and finally that his nose pressed the key. I next used the same procedure to walk him back to the other end of the box to press the setup key. In the final behavior, the rat would go to press the setup key and then run to other end of the box to produce the response key13. It took me two days to shape my first rat and two hours to shape my third. I had been shaped too. While I was reinforcing the rat, it was reinforcing me by doing what I wanted it to do.
The effects of reinforcement and shaping can occur with or without awareness. The organism is not necessarily conscious that his behavior is being altered. One apocryphal story tells of a large psychology class that decided to try shaping their professor. They all leaned back in their chairs looking disinterested. When the professor moved slightly to the left, they leaned forward in their chairs showing interest, which was their reinforcer. They then withheld reinforcement until he moved even farther left, and again leaned forward. Eventually, they had the professor standing in the far left corner of the room. The class then told him what they had done, and he was flabbergasted. The shaping occurred without any conscious awareness on his part.
The reason for spending so much time on contingencies and shaping is that they play a major role in behavior. For most humans, the major reinforcers are time-saving and efficiency, although different individuals may have specific reinforcers. These often affect safety through the process of "practical drift," where the actor (accidentally or purposefully) discovers that a slightly less safe behavior increases efficiency and results in no ill consequence. The actor then (accidentally or purposefully) behaves in even less safely and again is reinforced with greater efficiency and no harm. The process continues with increasingly unsafe behavior until a limit is reached. Like the rat in the Skinner box, the actor is shaped by the contingencies to increasingly unsafe behavior.
In the case of drivers, especially many motorcyclists, the reinforcements are feelings of control, of speed, and of power. The major punishers are collisions, delays, and traffic tickets. The contingent relationships between drivers and their reinforcers and punishers shape their behavior. This may create beneficial and efficient travel, but it also has a dark side because it can produce undesirable adaptations. The roadway is definitely a wicked environment-unsafe behavior is reinforced (speeding) while safe behavior is often punished (being cut off). Research (e.g., Rudin-Brown & Fletcher, 2013; Vaa, 2013) shows that operant learning can lead drivers to perform riskier as well as more efficient behaviors. It often leads to behavior that might be called "unsafe," but from a contingency viewpoint is perfectly rational. Since the shaping is usually unconscious, the drivers are unaware that they have learned "unsafe" behavior.
The only solution is to create reliable contingencies that are enforced. Since actual collisions are so rare, the best method of changing driver (and pedestrian) behavior is through the application of smaller reinforcers and punishments that can be delivered more often and more reliably. This is what traffic tickets are for. Some have already shown that changing contingencies is an effective way to modify road user behavior. Enforcing traffic rules with punishments increases driver yielding to pedestrians (Van Houten, & Malenfant, 2004), reduces red light running (Sze, Wong, Pei, Choi, & Lo, 2011), and promotes seatbelt usage (Shults, Nichols, Dinh-Zarr, Sleet, & Elder, 2004). Other measures such as speed bumps and rumble strips across the road change the contingencies by making high speeds less attractive. These measures would not be necessary if purely cognitive approaches to behavior change such as education and persuasion were highly effective.
A major cause of pedestrian and bicyclist collisions is their illegal street crossing. The only effective way of stopping this behavior would be to change the contingencies by handing out jaywalking tickets. The reinforcement of increased efficiency has to be overcome to effect behavior change. For all the lip service paid to safety, however, the political will to act is very low. In sum, operant learning often shapes driver behavior and adaptation to the roadway. Certainly, cognitive processes can also change behavior. Causal mental models of the world and social learning are other strong factors that influence behavior, but much of human adaptation occurs unconsciously through operant feedback from the environment. Like evolution, it selects the apparently best outcome from the random possibilities.
Implicit and Statistical Learning
Operant learning plays an important role in shaping behavior, but it is not the only form of human learning. The study of "naturalistic decision-making" (Klein & Zsambok, 1991) suggests that humans can learn important information without feedback from the environment. This "implicit learning" occurs as humans experience life. They unconsciously learn its statistics from their repeated exposure to different environments. This allows humans to build up "tacit" knowledge about what is normal and abnormal in many situations. This tacit knowledge, often results in an understanding of environments that cannot be easily expressed in words. For example, a driver unconsciously learns the frequency of seeing a pedestrian cross the road at a given intersection, the frequency of a car approaching from a given direction, the frequency that a lead vehicle will brake hard under different road conditions, etc. The tacit knowledge presumably contributes to generating the probabilities used in decision-making, to the development of the schemata that govern expectations and to learning system tolerances. Humans can also build up mental models that help aid in causal based reasoning. This tacit knowledge is presumably what separates novices from experts.
Humans may use this tacit knowledge to make decisions "intuitively," unconsciously without any deep thought or analysis. One decision technique is the recognition-primed decision-making (RPD) (e.g., Klein, 1997) mentioned here. The actor recognizes a pattern that he has experienced in the past and intuitively knows what to do. The hallmark of RPD is that the viewer does not consider alternative actions but simply chooses the one most likely to succeed. Afterward, the actor may find it difficult to explain his decision.
However, tacit knowledge and decision strategies such as RPD have limitations. One is that they require a kind world to develop, but most real-world situations are wicked to some degree. Second, emergencies often occur in circumstances that actor has never seen before. They cannot have learned to recognize the danger or to develop an adequate response.
Operant and implicit learning have differences and similarities. The obvious difference is that implicit learning requires no explicit feedback, although it might be supposed that having prior expectations confirmed is reinforcing since it creates more certainty. Expecting to see a pedestrian in a given location and then seeing one on the next occasion reinforces search to the location. Conversely, Operant and implicit learning predict the same outcome: viewers recognize situations and make decisions automatically with no conscious analysis.
Conclusion
Although cognivists have demeaned and dismissed operant psychology, it lives on. Philosopher Daniel Dennett (1975) was correct when he explained that "The Law of Effect Will Not Go Away."14 In the study of accident causation, for example, many (e.g., Dekker & Hollnagel, 2004) suggest that causal explanations based on observable behavior are more scientific and less prone to fallacy than are appeals to folk psychology models of inferred mental states. In the page What is Inattention?, I discussed this topic in more detail when examining the problems with using of "inattention" as a causal explanation.
Endnotes
1Edward Thorndike was an educational psychologist concerned with improving learning by strengthening the stimulus-response (S-R) connections between students and teaching materials (Thorndike, 1932). He proposed three major laws, the first being the Law of Effect. The second was the "Law of Readiness," (students learn more when prepared) while the third was the "Law of Exercise" (practice strengthens the S-R connection). Secondary laws included Primacy, Recency, Intensity, and Freedom.
2Thorndike originally used the terms "satisfier" "and "annoyance" instead of "reinforcer" and "punisher." Sometimes people will also speak of "rewards" rather than of reinforcers. However, behaviorists reject of such terms as being mentalistic and hence unscientific.
3Of course, a response could have no consequences, which could be mildly punishing due to the wasted effort or reinforcing if an expected bad outcome did not occur.
4The story goes that Skinner chose pigeons for his research because he could go up on the roof and get them for free. In my days as a pigeon runner, you had to order them in white from a specialized, and expensive, breeding farm, the Palmetto Pigeon Factory.
5"Autoshaping," as the name implies, occurs when a pigeon shapes its own behavior of learning to peck an illuminated key with no intervention. To start, the key illuminates and after a brief interval food appears (a grain hopper pops up). After this happens a few times, pigeons peck the key as soon as it lights up. They are treating the key as if it were the food, i.e., respondent conditioning had occurred. “Negative autoshaping" is the reverse contingency that leads to highly destructive behavior. After the pigeon has autoshaped and is responding to the illuminated key, the situation changes in a diabolical way. If the pigeons peck the key before the food appears, then none is delivered. In short, the pigeons get the food if they do anything else but peck the key. Yet despite this contingency, the pigeons can’t seem to help themselves and they continue to peck the key, cutting themselves out of the reinforcement.
6Notice that the term "addictive personality" is good an example of Folk Psychology circular reasoning. Why does the person compulsively gamble? Because he has an addictive personality. How do you know that he has an addictive personality? Because he compulsively gambles.
7However, much of human superstition is based on symbolism.
8Rats get something of a bad rap. The rats that most people think about are filthy, half-starved Norwegian rats who run around in gutters. When reasonably cared for, most rats strains are rather mild, highly social, and even friendly animals. Mice, on the other hand, may look cute but are highly territorial and can be quite vicious.
9There two contrasting methods of extinguishing phobias. In “systematic desensitization,” the phobic is exposed to the CS in gradual steps. For example, a person afraid of flying might even avoid airports. To overcome this, he may first be driven past the airport. Next, he later parks at the airport. Then later he enters the airport. The next day he walks through the terminal, etc., etc. until he finally gets on a flight. The opposite method is “flooding,” where the person is forced to immediately confront the CS so extinction can occur. The person might be taken straight to a seat on a flight. Of course, flooding is likely to create extreme anxiety, but it much faster—if it works.
10Total extinction probably never occurs. There is an old behaviorist metaphor that learning is like taking a sheet of fresh paper and crumpling it into a ball. You can try to press out all the wrinkles, but they never entirely disappear. Under stress the paper’s wrinkles reappear, i.e, the person regresses back to previously learned behavior which had once upon a time been successful.
11The casinos don't actually have to let anyone win. With a large number of players, some are bound by chance to win in their first few tries and get hooked into a VR schedule.
12Many addictions attributed to physiological factors often have some operant component.
13There was more to the shaping than is described here, as it involved an auditory discrimination. See a more detailed account of the entire experiment in Green, M., Terman, M. & Terman, J., (1979) Comparison of Yes No and Latency Measures of Auditory Intensity Discrimination, Journal of the Experimental Analysis of Behavior, 33, 363-372. The "experimental analysis of behavior" is an alternate name for the study of operant learning.
14This article can be retrieved from https://gwern.net/doc/philosophy/mind/1974-dennett.pdf.
A division of 2057949 Ontario, Inc.
Copyright © 2024 Marc Green, Ph. D.
Home Page
Contact Us